
Contents
Key Takeaways
AI proficiency is not about whether engineers use AI, but how they collaborate with it—successful engineers direct, verify, and refine AI output rather than blindly accepting it
The strongest predictor of task success was AI collaboration quality, with engineers who planned, prompted precisely, tested outputs, and corrected AI mistakes consistently outperforming those who delegated thinking to the model
AI usage patterns naturally cluster into distinct archetypes—from Directors and Unblockers who actively steer the process, to Delegators, Prompt-and-Pray users, and Skeptics who either over-trust or under-utilize the technology
Two separate skills determine effective AI collaboration: the ability to guide the AI effectively (planning, prompting, decomposition) and the ability to calibrate trust appropriately (verification, validation, error detection)
As AI becomes universal, hiring should focus less on AI access and more on observing how candidates use it in practice—the real signal lies in their process, judgment, verification habits, and ability to recognize when the model is confidently wrong
Part 1 of 2 · The gap
We watched ~70 engineers solve real coding tasks with AI, screen recording and all. The gap between the best and the rest had almost nothing to do with whether they reached for AI — and everything to do with how they held it.
Two engineers got the same problem: a sluggish FastAPI service backed by Postgres, make it fast. Same starter code, same clock, same open invitation to use whatever AI they wanted.
The first one opened a chat window, pasted the entire problem statement in, and asked it to fix everything. The AI obliged. It found the slow queries, named the missing indexes, proposed the rewrite. He copied the answers back into his editor, more or less unread, and moved on to the next thing the AI told him to do. He finished with something that mostly worked. He had been busy the whole time. He had also, in a way that's hard to unsee once you've watched it, never really been in the problem.
The second one — Vedang — didn't prompt at all for the first few minutes. He read the code, ran the failing endpoint, formed a hypothesis. Then he opened Gemini and asked for a plan: specific, scoped, full of constraints he'd derived himself. He read what came back, changed a couple of things, ran the tests, and corrected the model when it wandered. Our analysis described it almost admiringly — detailed prompts, meaningful engagement, thorough verification, real steering. He finished with a clean, correct solution.
Both of them "used AI." Only one of them was doing engineering.
The first engineer | Vedang | |
|---|---|---|
First move | pasted the whole problem, "fix this" | read the code, ran it, formed a hypothesis |
His prompts | generic — hand it the task | specific, scoped, his own constraints |
With the AI's output | copied it back, mostly unread | read it, edited it, tested it, re-steered |
AI-collaboration | 2 / 5 | 5 / 5 |
Task result | "mostly worked" | clean and correct |
That's the thing the entire AI-and-coding conversation keeps fumbling. "Do you use AI?" is a dead question — everybody does. The live one, the one that actually separates engineers, is how. And here's the uncomfortable answer, after watching close to seventy of them work: AI doesn't lift everyone equally. It widens the gap — between the engineers who direct it and the ones who merely accept it. The difference isn't taste or vibe. It's visible, it's consistent, and it shows up in the results with a clarity that genuinely surprised me.
Three things in the data convinced me, and I'll take them in that order. The skill is bimodal — you're good at it or you're not, with barely a middle. It predicts the outcome — how well someone collaborated with AI tracked whether they solved the task, almost in lockstep. And it resolves into five recognizable characters, sitting on two axes you can actually hire for.
We didn't ask them. We watched them.
A quick word on where this comes from, because it's the only reason any of it is worth reading. These aren't survey answers or self-reported habits. Engineers worked through realistic build tasks in a sandbox with their screens recorded, reaching for whatever AI tools they liked. We then looked at the texture of how they collaborated — not whether AI was used, but how good their prompts were, whether they read and adapted what came back, whether they ran and tested it, whether they caught the model when it went wrong. Around 85 task attempts in all.
Here's what fell out.
Most people aren't "pretty good" with AI. They're either good or they're not.
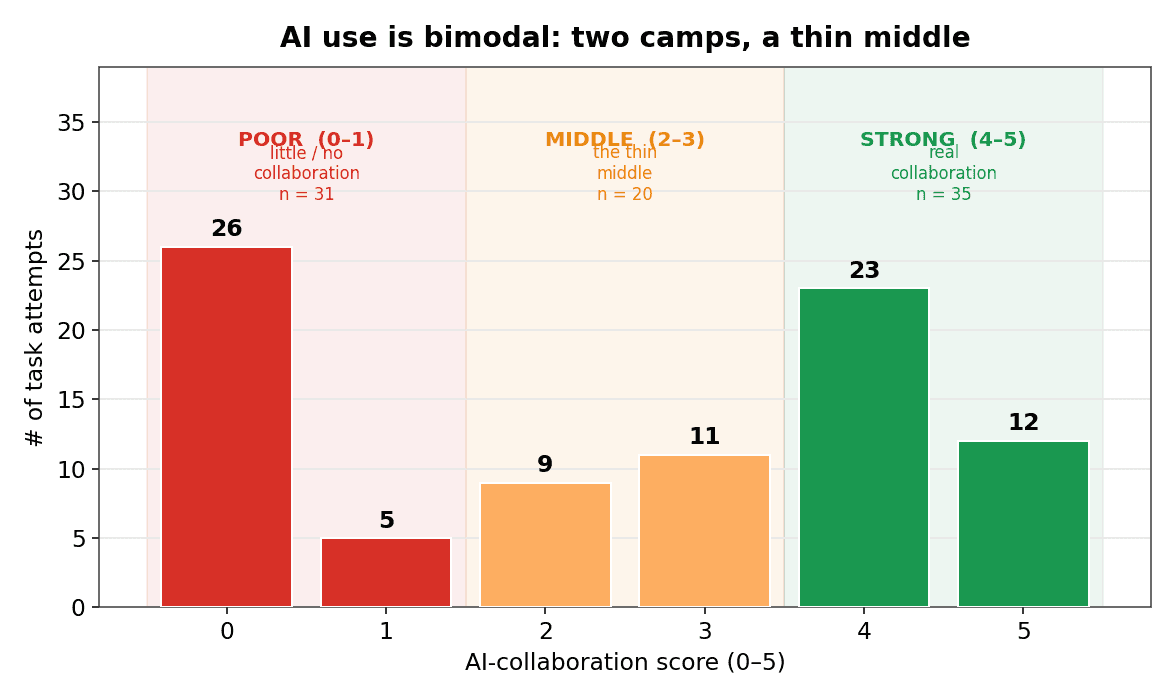
You'd expect a comfortable middle — a big hump of competent-enough people with tails on either side. That's not what we found. People split into two camps. Roughly four in ten collaborated genuinely well. Another third barely collaborated at all — technically using AI the entire session and getting almost nothing out of it. The competent middle, the "yeah, fine, gets by" zone, was the thinnest part of the distribution.
That shape matters more than any single score, because it kills the comfortable assumption that AI fluency is something everyone is quietly absorbing. They're not. The tool is the same for everyone. What people do with it is splitting the room in two.
Sort them by how they worked with AI, and you've nearly sorted them by who succeeded.
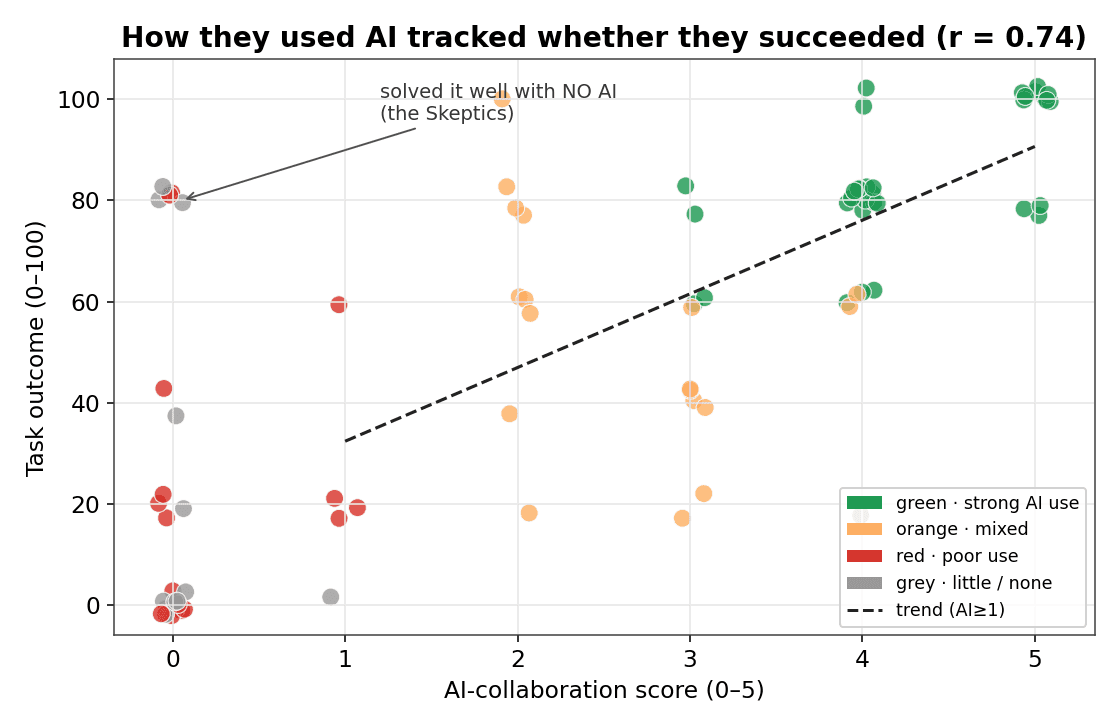
This is the part that stopped me. If you lined our engineers up from worst to best at collaborating with AI, you'd have very nearly lined them up from worst to best at solving the actual task. The two moved together, almost in lockstep. (For the statistically minded, the correlation was 0.74 — but the point isn't the decimal, it's that "how well they worked with the AI" predicted the outcome about as well as anything we measure.)
Remember: everyone here had AI. So this isn't "AI users win." It's that the quality of the partnership — not the access to the tool — is what tracked success.
Two honest wrinkles, because the chart shows them and I'd rather you hear it from me. The far-left column is murky: a zero can mean "tried nothing, gave up" or "quietly coded the whole thing by hand." Which brings me to Arthur — who used no AI at all, by choice, and still scored an 80, hand-writing his code and his tests. He's proof that competence doesn't live downstream of a chatbot. He's also, as we'll see, his own kind of cautionary tale.
The skill is really two skills — and they don't move together
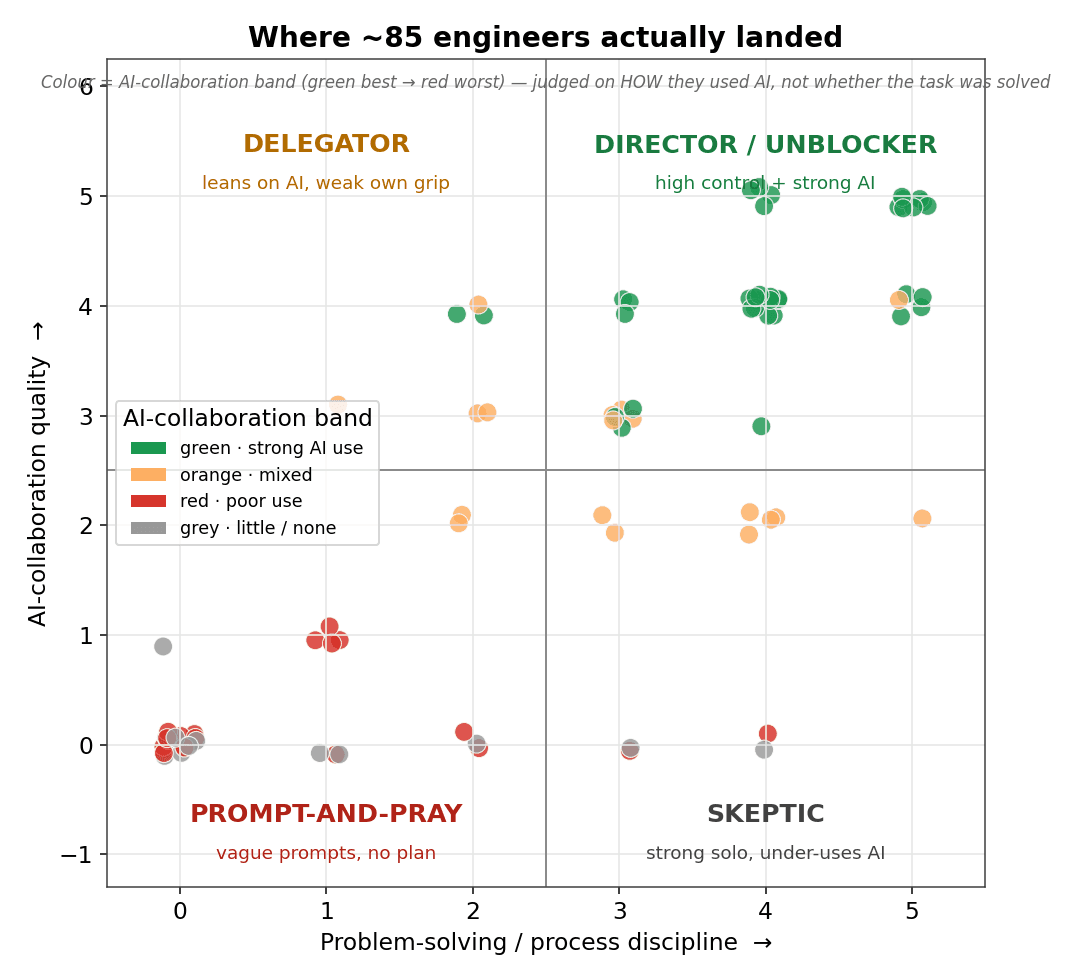
Stare at enough of these sessions and the same handful of characters keep walking on stage — five of them, each one a real person in our data. And they sort along two axes that move independently: how well you drive the AI (your prompts, your plan) and how wisely you trust it (your verification, your recovery). Hold those two axes in mind as you read the five — the entire map is built from them, and the reason you can't grade this with a single thumbs-up is that a person can score high on one axis and bottom out on the other.
Archetype | In our data | AI · Task | The tell |
|---|---|---|---|
Director | Vedang | 5 · 100 | plans, prompts precisely, verifies, steers |
Unblocker | (the green cluster) | 4 · 80 | uses AI to learn, keeps the wheel |
Delegator | Manthan | 2 · 60 | good prompt, blind acceptance |
Prompt-and-Pray | Aayush | 0 · 20 | "fix this," takes the code unread |
Skeptic | Arthur | 0 · 80 | distrusts AI even when it's right |
The Director. That's Vedang. Decomposes the problem, prompts with precision, plans before generating, verifies before trusting, and catches the model the moment it drifts. The prompt, for the Director, is the work — by the time the AI writes anything, the thinking is already done. This is the dense green cluster in the top right, and it's the one you want to hire.
The Unblocker. Sits right next to the Director, and is easy to confuse with over-reliance until you look closely. The Unblocker reaches for AI to learn — to understand an unfamiliar library, explore an approach, get un-stuck — but never hands over the wheel. They use it to think, then verify before they adopt. Different intent than the Director (discovery vs. acceleration), same discipline.
The Delegator. This was our first engineer — and his cousin Manthan, who pasted the problem and the code straight into ChatGPT, let it diagnose every issue, and copied the fixes back with, in the analysis's dry words, "minimal to no modification." Here's the uncomfortable part: Manthan's task came out mostly correct. He'd have passed a pass/fail screen. But his collaboration scored near the bottom — because the AI, not Manthan, did the engineering. The Delegator's tell isn't a bad prompt. It's blind acceptance.
The Prompt-and-Pray. Vague prompts, no plan, no decomposition, just "fix this" on a loop until something runs. Aayush is the clean example: he pasted the entire problem into ChatGPT, took the code back unread, and dropped page-component logic into an API route file — shipping something that simply didn't work. Where the Delegator fails by trusting too much, the Prompt-and-Pray fails before that, by never saying anything precise enough to trust.
The Skeptic. Arthur again. The mirror image of the Delegator: distrusts the AI even when it's right, sets it aside, does it all by hand. Sometimes — like Arthur — they're good enough to get away with it. But reflexive distrust is its own failure; you're paying for a power tool and using it as a paperweight. Most people's mental list of "AI types" forgets this one exists. The data doesn't.
The quiet lesson in that map: two different things are being measured, and they don't move together. How well you drive the AI (your prompts, your plan) and how wisely you trust it (your verification, your recovery) are separate skills. You can write a beautiful, surgical prompt and then accept a wrong answer without blinking. That's why the Delegator and the Prompt-and-Pray are different people, and why you can't grade this with a single thumbs up or down.
What this opens up — and what's coming in Part 2
If the quality of the partnership is what separates engineers, a harder question follows: what exactly is that quality made of, and why does it predict the outcome so well? The short version — and the whole of Part 2 — is that it lives in the process, not the product. How an engineer reaches an answer (the prompt trajectory, the plan, the moment they catch the model going wrong) predicts performance better than the answer itself — which is precisely the thing AI can now fake. That's the spear-tip, and it's where this series is really pointed: process > output.
(And later still, the ground shifts again. Agentic assistants — the ones that plan and edit across your whole codebase — already showed up in about a third of these sessions, and when the agent writes the code, at least two of these five archetypes collapse into each other. That's an essay of its own. For today, in the world most engineers still work in, the five hold.)
AI is a multiplier — and multipliers have a sign
We've spent two years arguing about whether AI makes engineers faster. Watching these sessions, I think that's the wrong question. AI doesn't lift everyone equally — it makes the gap wider. The same tool, in Vedang's hands, multiplies his judgment; in the Delegator's hands, it multiplies his mistakes, faster and more confidently than he'd ever manage alone. It's a multiplier, and multipliers have a sign.
So if you're hiring, stop asking whether people use AI. Watch how — how they prompt, what they check, what they catch when the machine is wrong. And if you're an engineer, the skill worth building isn't a bag of prompt tricks. It's the old, unglamorous stuff, now more valuable than ever: break the problem down, put your understanding into the spec, verify before you trust, and notice the exact moment the AI is confidently wrong.
Everyone has the tool now. The people worth betting on are the ones with their hands on the wheel.
A note on the method, and its limits
These scores come from analyzing the screen recordings themselves, not from asking people how they work. The sample is modest — about 85 task attempts from ~70 engineers, across a mix of tasks — and it's observational, not a controlled experiment; "did they solve it" is our own rubric. I'm sharing the direction the data points, not claiming a clinical result. The honest caveats are in the piece, not buried here.
Why we measure it this way — sources
White, J. et al. (2023). A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT. arXiv:2302.11382. — the backbone for prompt quality, decomposition, and verification as distinct skills.
Barke, S., James, M., Polikarpova, N. (2023). Grounded Copilot: How Programmers Interact with Code-Generating Models. OOPSLA 2023, arXiv:2206.15000. — "acceleration vs. exploration," behind Director and Unblocker.
Mozannar, H. et al. (2024). Reading Between the Lines (CUPS). CHI 2024, arXiv:2210.14306. — precedent that AI-coding sessions can be reliably labeled from recordings.
Microsoft Aether (2022). Overreliance on AI. — over-reliance and under-reliance, behind Delegator and Skeptic.
Parasuraman, R., Sheridan, T., Wickens, C. (2000). Types and Levels of Human Interaction with Automation. — automation complacency.
Lee, J., See, K. (2004). Trust in Automation: Designing for Appropriate Reliance. — trust calibration.
Schemmer, M. et al. (2022). Appropriate Reliance on AI Advice. arXiv:2204.06916. — telling correct AI output from incorrect: our "recovery."
Ferdowsi, K. et al. (2024). Validating AI-Generated Code with Live Programming. CHI 2024, arXiv:2306.09541. — the verification burden specific to AI code.
Chen et al. (2025). Controlled study of developer–agent interaction. arXiv:2507.08149. — the author→overseer shift.
Anthropic (2024–25). Measuring agent autonomy / Claude Code auto mode. — autonomy modes and the rubber-stamping risk.

Founder, Utkrusht AI
Ex. Euler Motors, Oracle, Microsoft. 12+ years as Engineering Leader, 500+ interviews taken across US, Europe, and India
Want to hire
the best talent
with proof
of skill?
Shortlist candidates with
strong proof of skill
in just 48 hours

